Sometimes you come across things that you wrote not so long ago that merely serve to reinforce how fast the world has moved.
Such as this from November 2022, just as ChatGPT was released to the world and I was getting my head around foundation models and what they were:
The connection that I see is that perhaps a foundation model trained for text summarisation could be specialised on a corpus of notes and used to summarise search results, progressing us beyond the “list of results”. Instead of answering the question “show me the notes containing X”, we can more directly ask our likely underlying question “what have I learned about X over time”.
I imagine an answer that summarises, over time, one’s notes, including references to source notes – for digging deeper – as it goes. In essence, can one use machine learning as a virtual librarian for one’s notes? While text summarisation is a poor man’s librarian, very few people are rich enough to afford a real human to look through their old notebooks! I can see this ability to summarise becoming a cornerstone of a workflow, and a way to start combining the best parts of incremental and evergreen note-taking models.
I can imagine taking this a further step forward with more advanced versions of models like ChatGPT, where one could hold conversation with the model to request more information on given topics in the summary. In this way, we take a step towards the types of interactions we see within shows like Star Trek, with a conversation tailored to one’s immediate needs.
How much more we can do today, just three years later: I have been using Claude to write a vector search for my Obsidian notes. AI is not just writing a summary, but is coding the application to use AI to write a summary 🙃
There is very rarely one “root cause” of an incident. And often, certain causes are harder to flag up than others:
The reason is not that “incorrect configuration value” is somehow objectively more causal than power dynamics. Rather, the sorts of things that are allowed to be labelled as causes depends on the cultural norms of an organization. This is what people mean when they say that causes are socially constructed.
And who gets to determine what’s allowed to be labelled as a cause and what isn’t is itself a property of power dynamics. Because the things that are allowed to be called causes are things that an organization is willing to label as a problem, which means that it’s something that can receive organizational attention and resources in order to be addressed.
– What’s allowed to count as a cause?
Bonus from the same site: You’ll never see attrition referenced in an RCA
They call them “god rays” when the sun pokes shards through cloud. I find they are often too subtle to catch on camera, but the black and white of this shot captures them perfectly.

Clifton suspension bridge, Bristol.
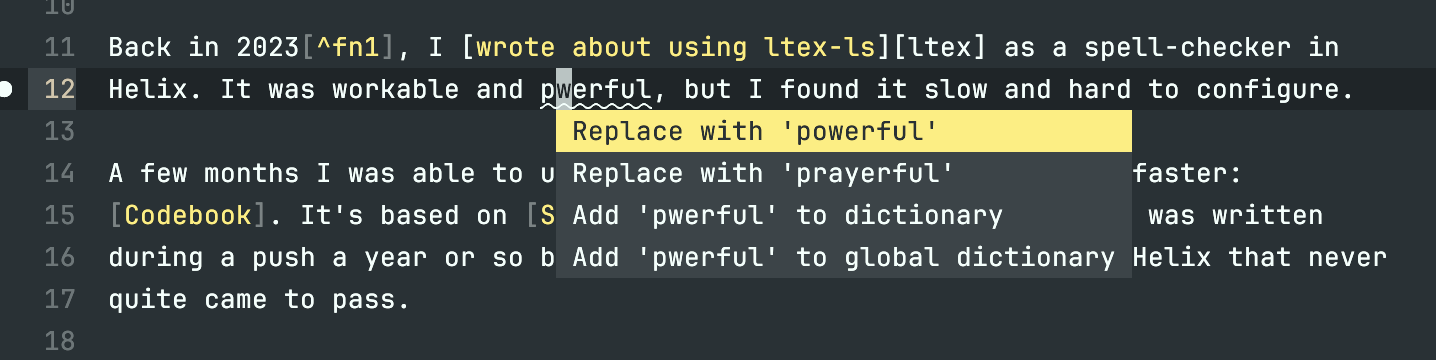
Back in 20231, I wrote about using ltex-ls as a spell-checker in Helix. It was workable and powerful, but I found it slow and hard to configure.
A few months I was able to upgrade this to something leaner and faster: Codebook. It’s based on Spellbook, which (mildly ironically) was written during a push a year or so back for inbuilt spelling support in Helix that never quite came to pass.
I highly recommend it. Codebook is a code spell-checker, so it recognises coding
idioms like snake_case_names and camelCaseNames, and uses tree-sitter so
it’s sensitive to what the purpose of each token is — so it doesn’t flag
keywords as bad spellings, for example. Codebook works great for markdown, too.
Once this is all set up, you’ll be able to hit space + a for completions:
After the fold is my configuration for a few (programming) languages in British English.
After writing about cgroups, it’s hard not to get sucked into the rest of the low-level Linux technologies that make up containers. In addition to cgroups, the main other technology is namespaces, which give processes different views of critical system resources.
For example, the mnt namespace allows us to isolate what mount points a
process sees (eg, give the process a new root file system — including special
mounts like proc), while the cgroups namespace allows us to isolate a
process completely to a new cgroup hierarchy. Other namespaces form further
pieces of isolating containers from each other and the host system. I hope to
write more about namespaces, and build a bare-bones container runtime.
(When writing the cgroups article I wondered how to prevent a process “escaping” its cgroup. I think this is our answer: give it its own cgroup namespace, and it cannot move itself outside its original cgroup).
For this post, we’ll look at the net namespace. There’s quite a lot to talk
about here, because in addition to the isolation provided by the namespace,
there are a number of low-level networking constructs we have to scaffold up to
allow a process in a namespace to talk to other network namespaces, the host
machine and, finally, the public internet.
What do I hope to gain? By piecing this together, admittedly by mostly adapting others’ work to my specific goals, I hope to get a more solid understanding of how container networking works, to help ground my mostly theoretical knowledge of Kubernetes overlay networks.
Let’s go.