A long time ago I read that you needed to see or hear something seven times before you’d take it in. It’s stuck with me.
I read a lot. Many of these things can be read once and then left to slowly accrete into my existing world view. But some I want to read again. Seven times, to make sure they go in.
For a year or so I’ve thought about writing an application to help with this, but never got around to it. I have added items to Omnifocus, but they get buried alongside other tasks. I wanted to work out a way to bring this… let’s call it “re-reading” into my usual processes.
About three weeks ago I came across two tools that excited me. Excited me enough to flounder about for things to build with them, and to pull “Seven Times” (for that is what I’d started to call it in my head) back to the surface. Those two things were Val Town and Xata.
But what would be my “usual process”? What user experience should Seven Times have? I am a heavy consumer of RSS feeds (using NetNewsWire and FeedBin). It took a while for me to connect the two, but once I’d had the idea of making Seven Times an RSS feed, I couldn’t shake it.
So here’s our goal: articles to be re-read appear in NetNewsWire, on my Mac or phone:
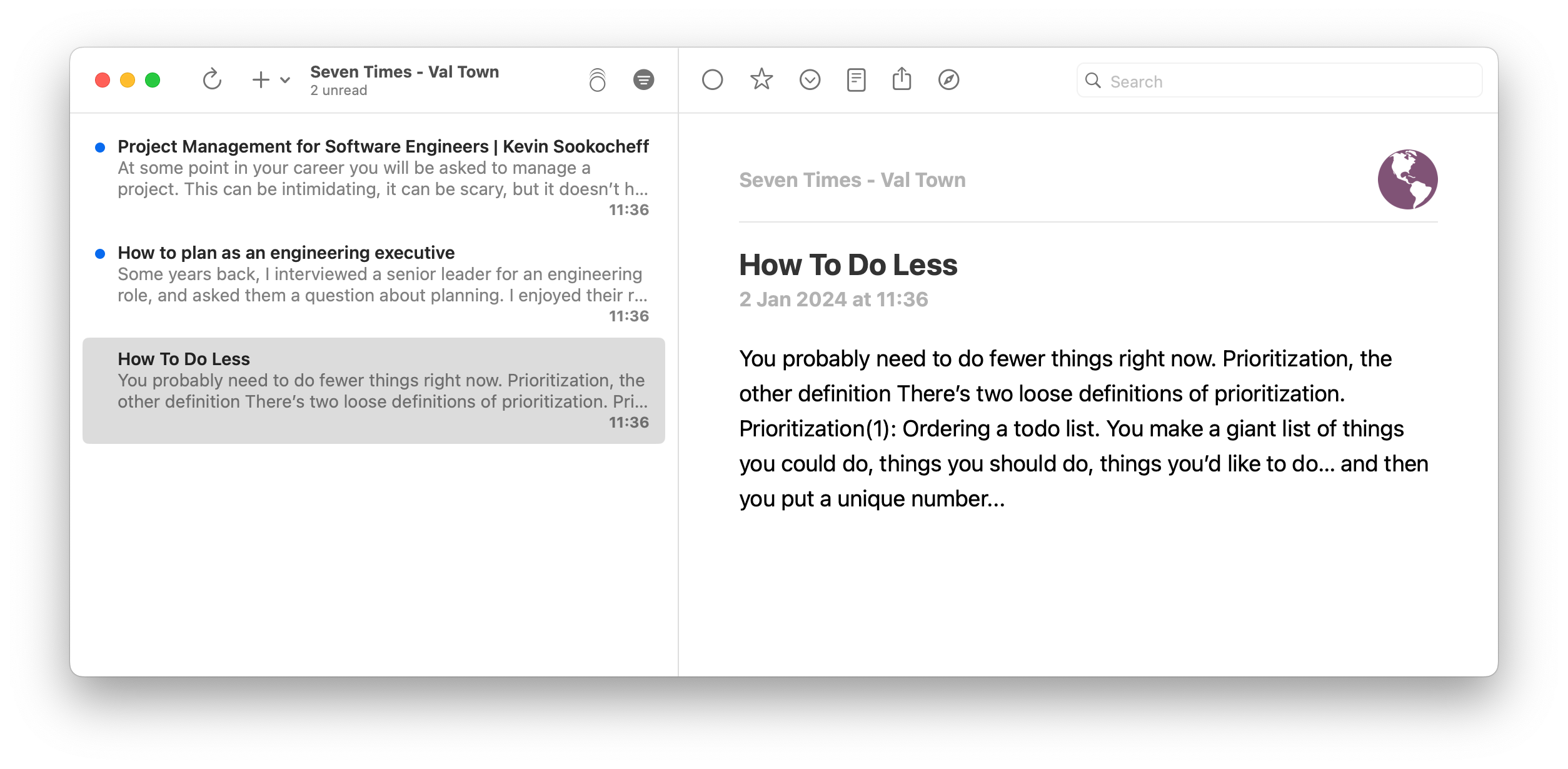
That screenshot isn’t a mockup, so let’s talk about Val Town and Xata, and how I used them to build a simple — but completely usable for just me — version of Seven Times in under a day.
The tools
Xata
Xata is a database as a service focused on user experience. It’s built on Postgres and ElasticSearch (architecture). I liked the UX focus, it allowed me to create and account and have a database up and running in under 30 minutes.
Xata’s focus is on a GUI management for data and databases. While I’d usually work with command line tools and SQL, I found the GUI management allowed me to quickly build out the simple data model for Seven Times without figuring out things like “how do I connect to this”. It also allowed me to “cheat” a bit and avoid writing UI where I could instead leverage Xata’s data editing.
Secondly, Xata provides a HTTP interface on top of their database, rather than vanilla Postgres or ElasticSearch. I found this appealing, it allowed me to get started really easily given my experience with CouchDB which is another HTTP-based database API. It also meant that it was possible to use Xata from Val Town.
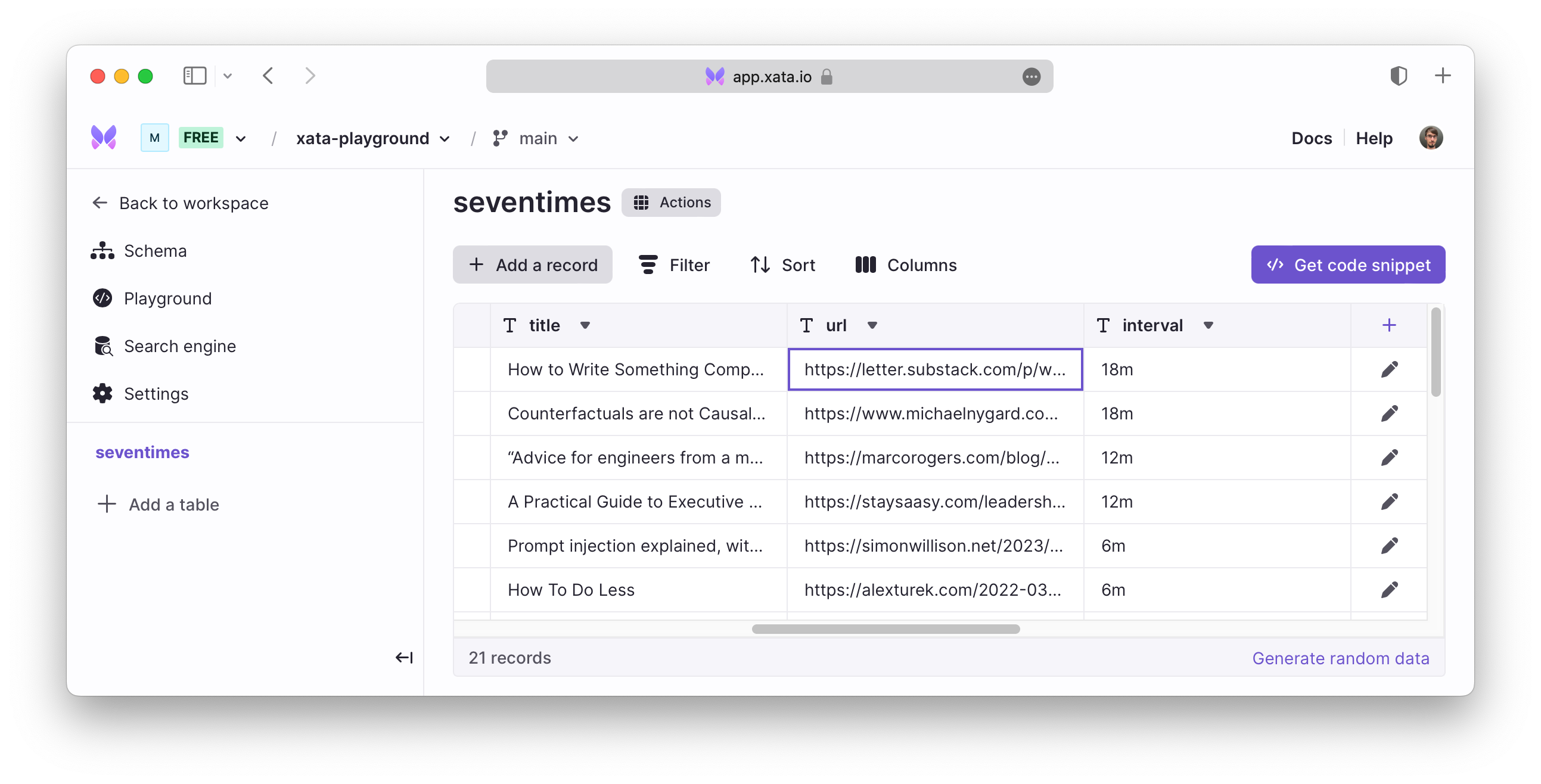
So Xata meant that I could easily create the persistence layer for my app. What about the runtime?
Val Town
Val Town, on the other hand, advertises itself as:
If GitHub Gists could run. And AWS Lambda were fun.
And I think that they achieve it! It is like writing a Gist that is executable. And the iteration loop is so fast that it’s really fun.
Code has to be JavaScript or TypeScript, and it’s run in Deno behind the scenes. This means that if a library runs in Deno, it’ll probably run in Val Town’s restricted environment (eg, no filesystem writes). So there’s lots of code — including Xata’s SDK — that’ll run inside Val Town. Having access to Deno’s ecosystem is a real win for getting apps like Seven Times off the ground.
Like Xata, Val Town is currently very GUI focused — you can only write code in their editor via your browser. But they make up for it: creating a webhook is two steps:
- Click “Create HTTP Handler”
- Write your logic.
- There is no step 3 — the code gets a URL right away and is callable.
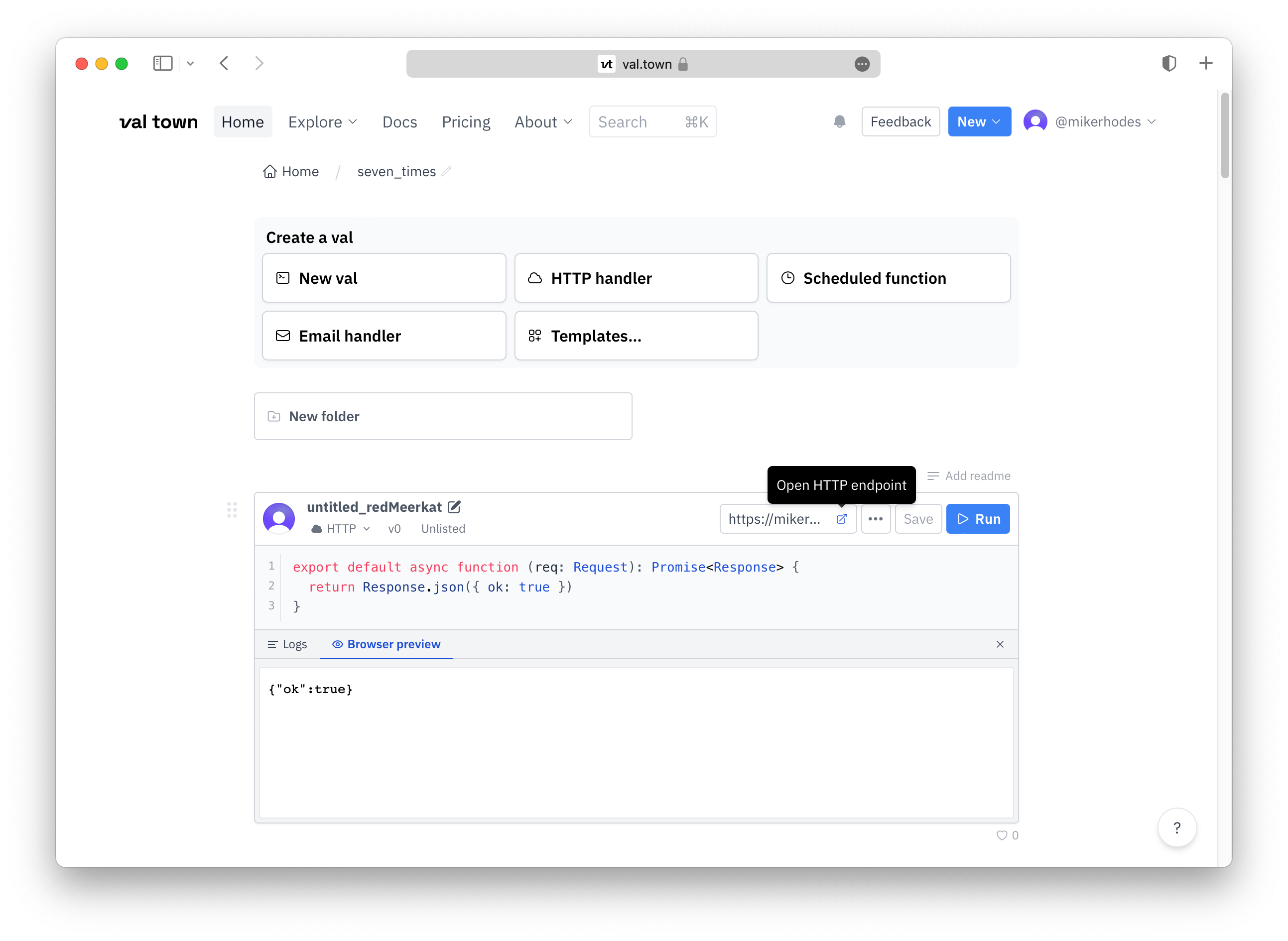
What got me here is that there is almost no friction in getting code up and running. The service has been around since mid-2022, so is quite young, but is polished for that. Like Xata, there’s clearly a heavy focus on the experience. Once you click “Create” you are presented an editor — CodeMirror maybe — and can start writing JavaScript or TypeScript. The code for a HTTP handler starts ready to go immediately (and it can be run immediately too).
Val Town calls these runnable snippets “vals”. Here’s the boilerplate HTTP handler val:
export default async function (req: Request): Promise<Response> {
return Response.json({ ok: true })
}
You can create other types of “val”. Standalone scripts (which can be imported into other scripts), cron jobs and email handlers. There’s a large library of examples and, as half the idea is sharing vals with others, an even larger library of user snippets that cover a lot of bases (eg, “how to use library X in the Val Town environment”).
Why was this good?
While it was pure chance that I came across them at the same time, it was fortunate: Val Town and Xata seemed cut from the same cloth and were begging to be stitched together, and Seven Times seemed to be the app I could do that with.
For a simple app like Seven Times, the basic impediment to progress is the debugging loop. The ability to instantly alter the Xata schema and, especially, Val Town’s loop of “type and then immediately run (then fix)” enabled me to progress super fast 🚀
One thing I noted with Val Town is that once you save a val, calls to that val
via curl immediately use that code. There’s no waiting around for
propagation of the code. That was really, really, really good. Waiting for
code to be deployed is a motivation killer.
It was a really great development experience. I loved it.
Now onto the app, so you can see what a Val Time app looks and works like. The basic thing is that we can easily stitch together vals into one application, either explicitly by calling one val for another, or implicitly, for example by using cron jobs as background tasks. Here’s how I put Seven Times together. It’s not much code but, well, that was one of the cool things about this whole exercise: spending a day to build an app I’d been trying to get myself to build for a year 🌟
Seven Times
As I noted, I wanted Seven Times to be a part of my day to day. I decided to do that by exposing my Seven Times re-read articles using RSS feeds, as I read those almost every day.
So the spec was set: allow adding URLs to a database, and expose the items that are “due” to be read via RSS. Each item can have an “interval”, and when I’ve read the item, it’s rescheduled again to be read after that interval. So I can set up an item just once with a URL, title and interval, and have it repeatedly pop up in my RSS reader.
Things we will need to do:
- Allow adding items to Seven Times.
- Write code to generate a feed for unread items.
- Write code to mark an item read and reschedule that item for future reading.
- Write code to download article content so it can go into the feed (this makes it easier to decide what to read, as likely I’ve forgotten after 12 months).
Data model
Seven Times pivots around its data model. It’s very simple at heart!
title string
url string
interval string
dueAt datetime
isRead boolean
readAt datetime
content text
contentDownloaded boolean
contentDownloadedAt datetime
The title, url and interval are input by the user. The other fields are
managed by various Val Town vals.
The interval value can be specified in days or months using a d or m
suffix, like 12m. Months are typical, days mostly allow us to test things are
working.
To create this table, I logged in to Xata on the web, created a new Database and
added a seventimes schema (table) to it. Creating the columns is a manual
GUI-driven process, but that worked great as I was iterating the schema as a I
went (eg, it took one iteration of the app to realise that a content downloader
was needed, and so the content* fields).
All in all, it took about five minutes to create the original schema and another five minutes of edits over time to get to the final schema. I also spent about twenty minutes exporting and munging my Omnifocus “re-read” tasks so I could import them into Xata via CSV.
Adding items to Seven Times
I cheated on this 😬
I just decided that I’d use the Xata UX to add rows for new items directly to the database, as and when I needed them. This saves a lot of code, given it’d need a simple form and a backend handler to manage this. (A lot of code is, of course, relative: we only have a hundred or so lines of code in this app!).
Connecting to the database
Connecting to a Xata database is relatively easy from JavaScript in Val Town, as it’s over HTTP so everything is built in. While one could make raw HTTP calls, the Xata JS SDK has useful affordances like database typing. We can use the Xata CLI tool to generate boilerplate code, including creating types for our database tables.
We create this as a reusable module using a “script” val in Val Town. Our other
code will be able to import and use the getXataClient method to retrieve a
client for us to use.
There’s quite a lot of boilerplate in this code the Xata CLI generated. The
important bits are the tables variable at the start where we define our schema
(this is just used for type inference in JS as far as I can tell), the
defaultOptions where we pull the database URL and creds from Val Town
environment variables, and the getXataClient below.
import { buildClient } from "npm:@xata.io/client@latest";
import type { BaseClientOptions, SchemaInference, XataRecord } from "npm:@xata.io/client@latest";
const tables = [
{
name: "seventimes",
columns: [
{ name: "title", type: "string" },
{ name: "url", type: "string" },
{ name: "interval", type: "string" },
{ name: "dueAt", type: "datetime" },
{ name: "isRead", type: "boolean" },
{ name: "readAt", type: "datetime" },
{ name: "content", type: "text" },
{ name: "contentDownloaded", type: "boolean" },
{ name: "contentDownloadedAt", type: "datetime" },
],
},
] as const;
export type SchemaTables = typeof tables;
export type InferredTypes = SchemaInference<SchemaTables>;
export type seventimes = InferredTypes["seventimes"];
export type seventimesRecord = seventimes & XataRecord;
export type DatabaseSchema = {
seventimes: seventimesRecord;
};
const DatabaseClient = buildClient();
const defaultOptions = {
databaseURL: Deno.env.get("SEVENTIMES_DB_URL"),
apiKey: Deno.env.get("XATA_API_KEY"),
branch: "main",
};
export class XataClient extends DatabaseClient<DatabaseSchema> {
constructor(options?: BaseClientOptions) {
super({ ...defaultOptions, ...options }, tables);
}
}
let instance: XataClient | undefined = undefined;
export const getXataClient = (options?: BaseClientOptions) => {
if (instance) return instance;
instance = new XataClient();
return instance;
};
Aside on importing vals
The really neat thing about this val is that we can use it from our other vals:
import { getXataClient } from "https://esm.town/v/mikerhodes/st_getXataClient";
// later ...
const client = getXataClient();
One important thing is that vals can be public or private. Private vals can only be imported by your own code. Public vals can be imported by anyone.
Most of the vals I created for Seven Times are Private, so the links in the code snippets won’t work for anyone but me. I wasn’t quite sure about making them public, so I left it private so I didn’t have to think about it deeply 😅
Downloading content
We can use Mozilla’s readability library to grab an excerpt from the articles we have in Seven Times. Later, we can embed that excerpt in our feed.
To use readability, we create a script val that exports a fetchReadable
method. Actually, we can do one better and reuse someone else’s val. Here’s
the one I used:
(Vals are versioned. This is version 26, and when you reuse a val, you encode
the version you are importing into the import URL in your code, to avoid it
being changed under you. If you go to follow the link in the embed to this val
itself, you’ll see there are newer, possibly improved versions. For my purposes,
this version worked, so I kept using it).
Now we have a function to download and parse the HTML for our re-read articles, we need to download content and save it to the database. The solution I opted for is to have a cronjob that downloads content for items. As items in Seven Times are added so that they can be re-read months later, it doesn’t matter that we might take a few hours to download the content. The steps are:
- Find unread items without content.
- Use
fetchReadableto get the content.
The relevant fields form our schema are:
isRead - only download content for items that are unread
content - where we store the content
contentDownloaded - record that we have downloaded content for this
contentDownloadedAt - record when we got it
Although Val Town has a pretty generous free tier, I opted to have an extremely low-usage version of downloading content — we’ll download one article per cron run, which I set to once per hour. So if we add several items in one go, it’ll take a few runs — and so a few hours — to download them all.
After we get the content, we update the record in Xata to set
contentDownloaded to true and also set the date it was retrieved (maybe
it’ll come in handy 🤷). That all gets saved back to the Xata database along
with the downloaded content.
// Note again how we reuse code from other vals by importing it:
import { fetchReadable } from "https://esm.town/v/hvlck/fetchReadable?v=26";
import { getXataClient } from "https://esm.town/v/mikerhodes/st_getXataClient";
// Val Town will run the `default` exported function for a cron job
export default async function(interval: Interval) {
const xata = getXataClient({ branch: "main" });
// Find unread items without content
const item = await xata.db.seventimes.select(["id", "title", "url"])
.filter({ isRead: false, contentDownloaded: false })
.getFirst();
// If there is no item, `getFirst` returns null
if (item === null) {
console.log("All unread item content downloaded; exiting");
return;
}
// Fetch content from the web
const content = await fetchReadable(item.url);
// Set the discovered content excerpt as the content stored
// in the database. This reduces storage costs over whole
// items.
const updated = await xata.db.seventimes.update(item.id, {
content: content.excerpt,
contentDownloaded: true,
contentDownloadedAt: new Date().toISOString(),
});
// If `update` returns null, that means we failed to update the record
if (updated === null) {
console.log("Error: couldn't update record");
} else {
console.log(`Saved content for ${item.title}`);
}
}
Generating the feed
I chose to generate a feed using the JSON feed standard. The standard is pretty pragmatic and requires few fields. Also, JSON is much easier to generate using JavaScript than XML is!
The relevant fields in our schema are:
id - so we can make a markread link
title - for the feed
content - also for the feed
dueAt - we only want to select items already due...
isRead - ...that are not already read...
contentDownloaded - ...and have their content ready.
Those watching carefully will have noticed that there’s no url in the above.
Why’s that? Because I needed some way to have the user mark that they’d read the
item. What I opted to do was make the link in the feed call a Val Town handler
which handles marking the item read and then responds with a 302 redirect to
the original article. I include only an excerpt from the article to re-read in
the feed to make sure the user visits the link.
I created a method to encapsulate generating the feed as a script val. Later,
we’ll create a single web handler that imports this val and calls the exported
feed function:
import { getXataClient } from "https://esm.town/v/mikerhodes/st_getXataClient";
// Generate the feed in response to a request
export async function feed(req: Request): Promise<Response> {
// Return max 100 items for the feed.
const xata = getXataClient({ branch: "main" });
const page = await xata.db.seventimes.select(["id", "title", "content"])
.filter({
"dueAt": { $le: new Date().toISOString() },
"isRead": false,
"contentDownloaded": true,
})
.getPaginated({ pagination: { size: 100 } });
const records = page.records;
// Now we have the records, make them into feed items.
// Note how we use the `markread` handler as the link.
const items = records.map(x => {
const readURL = `https://mikerhodes-seventimes.web.val.run/markread/${x.id}`;
return {
"id": x.id,
"title": x.title,
"url": readURL,
"content_html": x.content,
date_published: x.dueAt,
};
});
// Embed the items into a JSON feed envelope and return it.
return Response.json({
"version": "https://jsonfeed.org/version/1.1",
"title": "Seven Times - Val Town",
"home_page_url": "https://dx13.co.uk/apps/seventimes",
"feed_url": req.url,
"items": items,
});
}
Marking items read and rescheduling
When we follow the link in the feed, we hit the markread handler. This has a
few jobs:
- It marks the record identified by the ID in the URL as read.
- It creates a new record for the next time we should read it.
I opted to create new records for each new read scheduling so I could have a history of previous times I’d read the item. This means that we will have an ever-growing database, but given we’ll be adding a row for each item every few months or even yearly, I don’t think this is an issue even if we don’t ever create any database indexes.
Again, I created this as a script val to import and call later:
import { Chrono } from "https://deno.land/x/chrono@v1.3.0/mod.ts";
import { getXataClient } from "https://esm.town/v/mikerhodes/st_getXataClient";
export async function markRead(recordId: string): Promise<Response> {
// Try to pull the record we're marking read, failing if
// it doesn't exist.
const xata = getXataClient({ branch: "main" });
const updated = await xata.db.seventimes.update(recordId, {
isRead: true,
readAt: new Date().toISOString(),
});
if (updated === null) {
console.log("Error: couldn't update record");
return Response.json({ ok: false }, { status: 500 });
}
// Use the existing record's interval to schedule the next dueAt
let dueAt = new Date(new Chrono().addMonth(12));
if (updated.interval.endsWith("m")) {
dueAt = new Date(new Chrono().addMonth(parseInt(updated.interval)));
} else if (updated.interval.endsWith("d")) {
dueAt = new Date(new Chrono().addDay(parseInt(updated.interval)));
} else {
console.log("Did not recognise interval %{updated.interval}; using default.");
}
// Create a new record from the existing one, with the new dueAt.
const rescheduled = await xata.db.seventimes.create({
interval: updated.interval,
title: updated.title,
url: updated.url,
dueAt: dueAt.toISOString(),
});
if (rescheduled === null) {
console.log("Error: couldn't reschedule record");
return Response.json({ ok: false }, { status: 500 });
}
// Redirect the user to the original website so they can
// actually read the item.
return Response.json(
{ ok: true },
{ status: 302, headers: { "location": rescheduled.url } }
);
}
Create the web handler to pull it all together
We need to be able to call the feed and markRead methods from our script
vals from the internet. We’ll subscribe our feed reader to the feed URL. We
need to be able to call the markRead method to tell Seven Times we’ve read
that article.
To do this, we’ll create a single web handler val that imports the feed and
markRead vals and calls them. We’ll use a tiny router called
itty-router that was originally created for CloudFlare Workers.
To find out how to use itty-router in the Val Town environment, I searched Val
Town and found this example. This is a great demonstration of the community in
Val Town — many libraries have little demo vals like this. I used
a similar one for Xata.
Adapting this to our needs:
const { Router, json, error } = await import("npm:itty-router@4");
import { feed } from "https://esm.town/v/mikerhodes/st_feed";
import { markRead } from "https://esm.town/v/mikerhodes/st_markread";
export default async function(req: Request): Promise<Response> {
const router = Router();
router
.get("/feed", () => {
return feed(req);
})
.get("/markread/:recordId", (request) => {
const { params } = request;
return markRead(params.recordId);
})
.get("/", () => json({ ok: true, msg: "hello world!" }))
.get("*", () => error(404, "Not found"));
return router.handle(req);
}
Itty is an interesting router. It will call matching handlers until one returns
a value. So we create our app by chaining the handlers together rather than
attaching them individually. If /feed matches, the lambda is called. If it
returns a value (which it always does) then processing stops. We have a *
handler at the end, which ensures that there is some response to all requests.
Summary
And that was all it took to realise the Seven Times app. Given the way I decided to use the Xata UX to add new re-read articles and the way there’s essentially zero UX outside the feed reader, this isn’t exactly a mass-market production application.
But it did show just how easy it was to create using Val Town and Xata. There was very little that got in the way of my building this little application. No uploading JavaScript, waiting for deployments, running database migrations, working out how to use an API gateway to expose my code to the internet. None of that stuff. Just writing the code and building the schema.
I’d love to think about how this could be taken further, and I’m looking forward to finding more things to use Val Town and Xata in future. And because it is such low friction, it might allow me to build other things I’d not otherwise make. Actual, non-ironic, joy 😀.