Two weeks in and I’ve got through about three and a half chapters from Build a Large Language Model (from scratch). As I suspected, it’s a much more time-consuming — frankly, just harder — read than AI Engineering was. I’ve spent about an hour each night with both the book and a collection of background reading. While challenging, it’s been really fun getting properly into this topic. I look forward to my daily hour of struggle!
I’ve written up a few brief thoughts on what I’ve read so far.
Chapters 1 & 2: introduction and embeddings
The first two chapters are relatively straightforward, although I found myself having in-depth discussions with Claude (via rapport) about various aspects of embeddings while reading chapter 2. Here’s a sample of my conversations:
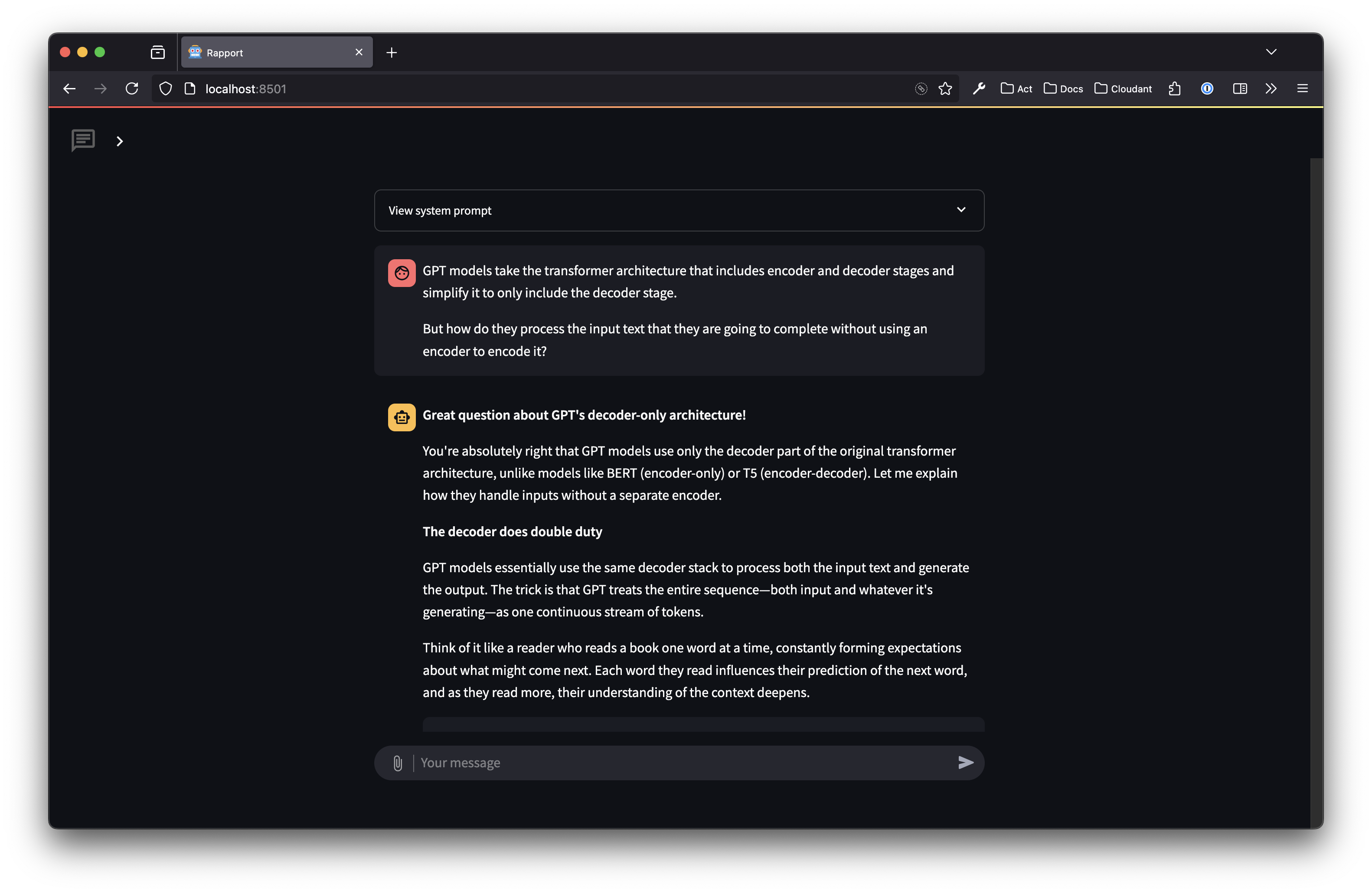
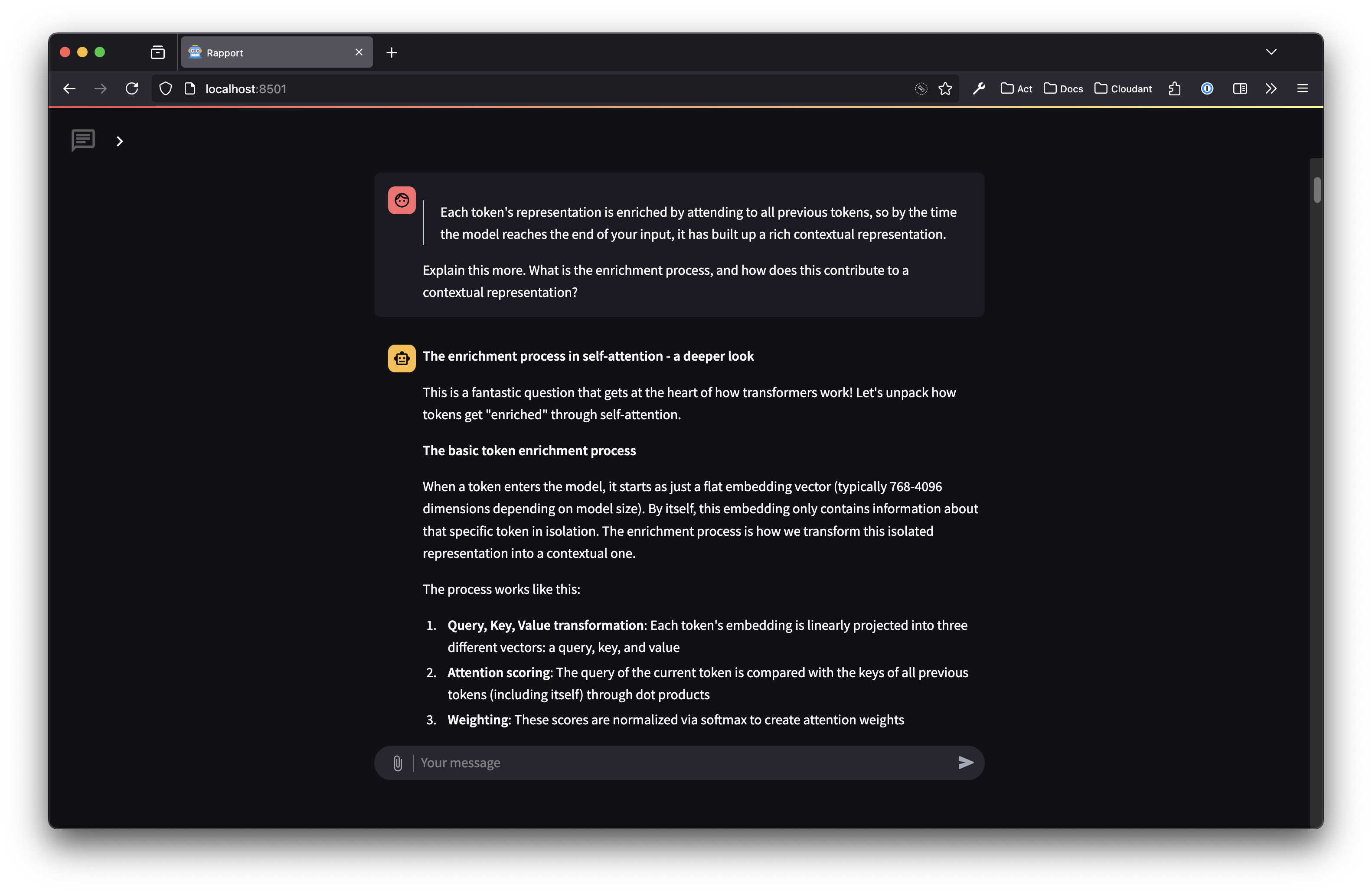
Overall I found these chapters, and the code, easy to follow. Although when I try to think about how embeddings could contain meanings I quickly tie myself in knots. But LLMs show that — somehow! — it seems to work. I’m reminded of the “shut up and calculate” school of thought in quantum physics: the maths works, focus on that rather than what quantum mechanics actually looks like in the physical world. Trust in the embeddings/weights/context vectors and don’t think too deeply! (But I find it hard to fully embrace this).
Chapter 3: self-attention
Chapter 3 has required much greater time investment. This is where the book starts to build a self-attention module. My last in-depth work on machine learning was back in 2004 during university, and deep learning didn’t really take off until the 2010s. So while I had heard of things like recurrent neural networks, convolutional networks and self-attention, if I’m honest with myself I would need to admit that they were really just abstract terms for me.
Chapter 3 has therefore involved quite a bit of learning beyond the book. While one could just follow the implementation that the book focuses on, I want to more background and to develop a better feel for the concepts.
While reading chapter 3, I’ve found the blog Giles Thomas absolutely invaluable. He’s also reading Build a Large Language Model (from scratch), and journaling his journey to understanding. I’ve found his notes spot on for the level of background I needed. I’ve read these alongside Claude, Wikipedia and revisited the relevant maths — my maths is super-rusty. His dives into parts of the machine learning research I’ve missed out on since university have been essential to my understanding.
I suspect this blog will continue being a major reference for me as I progress further 🤩.
Many, many thanks Giles!
Overall I now feel that I kinda-sorta understand the creation of context vectors
using weight matrices against the input embeddings (token + positional
embedding). That said, I had to double-check with Claude that my intuition about
what context vectors (and embeddings) really mean was accurate. In my question
to Claude, below, W_q is the weight vector that is multiplied by the input
embedding to create a query vector used during self-attention:
It feels like whatever things we suggest
W_qrepresents are guesses, though, because in the end,W_qis generated by the training process refining a set of values in a matrix. We might think that a good thing forW_qis that it’d help the model figure out about what pronouns refer to, and while it might well be doing that, we can’t know for sure. All that has happened is that the training process has produced a set of weights that have been shown to somehow minimise the loss function. But we can’t know precisely what those numbers really mean, or perhaps they don’t mean anything we might understand, the model might have some completely different way of comprehending the sentences that isn’t based on syntax relationships.Possible or complete rubbish?
(Side note: I love how Claude can take stream-of-thought gibberish and make sense of it).
Claude’s answer, backed up with other sources, broadly confirmed that yes, we don’t know the deeper meaning of the values in the vectors and matrices.
I’d like to read some of the more recent research in this area, however, because papers like Anthropic’s Golden Gate Claude suggest we are able to do some interpretation of the learned weights. I’d like to re-read this paper, armed with greater knowledge of relevant concepts.
It’s worth taking a side-track for this paper, it’s just such a nice one. Here’s an extract from Anthropic’s post about Golden Gate Claude showing evidence that the authors’ tweaks to Claude’s weights really did make it over-focus on the bridge:
And as we explain in our research paper, when we turn up the strength of the “Golden Gate Bridge” feature, Claude’s responses begin to focus on the Golden Gate Bridge. Its replies to most queries start to mention the Golden Gate Bridge, even if it’s not directly relevant.
If you ask this “Golden Gate Claude” how to spend $10, it will recommend using it to drive across the Golden Gate Bridge and pay the toll. If you ask it to write a love story, it’ll tell you a tale of a car who can’t wait to cross its beloved bridge on a foggy day. If you ask it what it imagines it looks like, it will likely tell you that it imagines it looks like the Golden Gate Bridge.
It feels like perhaps we’re starting to be able to decode what’s going on, although very roughly, and it’s still very much cutting edge research.
(Prior to reading the paper again, here’s a guess as to how they found the weights: fine-tune the model to produce golden gate answers and evaluate the changes in weights. Alternatively, perhaps they created a fancy way to trace the context vectors generated in the model’s layers for inputs referring to the Golden Gate. But it’s probably something different; I just wanted to record some guesses that come to mind so I can see if I’m anywhere close.)
Right now I’m spending about an hour each evening enjoyably slogging through the weighted self attention code, and moving onto causal attention and then multi-headed attention (skimming ahead, I suspect multi-headed attention will blow my mind 🤯).
(My notes on the book have reached 2,500 words of bulleted stream-of-consciousness, and later sub-bullet updates and corrections. I applaud Giles for managing to write up his notes onto his blog in an intelligible form!)
Onwards!