Again, most of my spare time was dedicated to AI learning and experimenting:
- I continued reading and coding from Build a Large Language Model (from scratch).
- I updated Rapport, my home-brewed chatbot app, a few times. I added a couple of major features and several quality-of-life improvements. I really like it now.
- I did some further work on my codeexplorer ai-toy. Now you can ask a model to edit code, and I added support for more providers than just Anthropic. However, experimentally, Claude is still one of the best models for code editing.
Building a Large Language Model (from scratch)
In my last post, I talked about getting to the complete architecture of the Large Language Model one builds while reading the book, but in its untrained state. I spent the next few days’ spare hour working through loading OpenAI’s post-training weights into the model, which obviously improved its output significantly!
However, the model we’ve built is still primitive. And, of course, it’s very small at 124 million parameters (albeit the code in the book allows loading up the weights for the 1.5 billion parameter model too; I didn’t try that yet to compare). The small model still very much feels like it’s doing basic prediction, while even GPT 3.5 (the original model for ChatGPT) was way more advanced in its ability to converse.
Still, even the small model feels quite magical for what it can produce. Perhaps again this is just because we humans want to believe that generating sentences — a special skill of ours — is harder than it really is.
While there are still two more chapters remaining — the first, fine-tuning for classification; the second, fine-tuning in an “instruct” style — for now I’m taking a breather. It was an intense experience getting this far in the book, and I feel I need a bit of time to digest it. I’d also like to lighten up my evenings a little.
I’m sure I’ll come back to the fine tuning sections, because I want to understand this process in more depth. However, I think I’ve got a lot of what originally drew me to the book (“just how is an LLM made?”), so I’m happy to take a step back.
Rapport
I added a bunch of new features to Rapport, supporting a new provider and a lot of quality-of-life features and fixes:
- I used ChatGPT to generate a logo. It’s cute!
- Added support for OpenAI.
- I added prompt-caching for Anthropic which significantly speeds up inference in long conversations, and reduces costs.
- Added the ability to customise the prompt by adding details to it. I used the
new editing features of
codeexplorer.pyto get me started with this (see below). - Cribbed some of Claude’s prompt to improve Rapport’s. While you can use other models with Rapport, I like Claude’s style. Taking some of the basic instructions like “Don’t immediately explain code, but ask the user” and “Rapport likes to converse with the user about topics” are small interaction improvements.
- I fixed an obscure bug upgrading from 1.43 of streamlit to higher versions. One of those things that was a one-word fix, but finding that fix to about an hour.
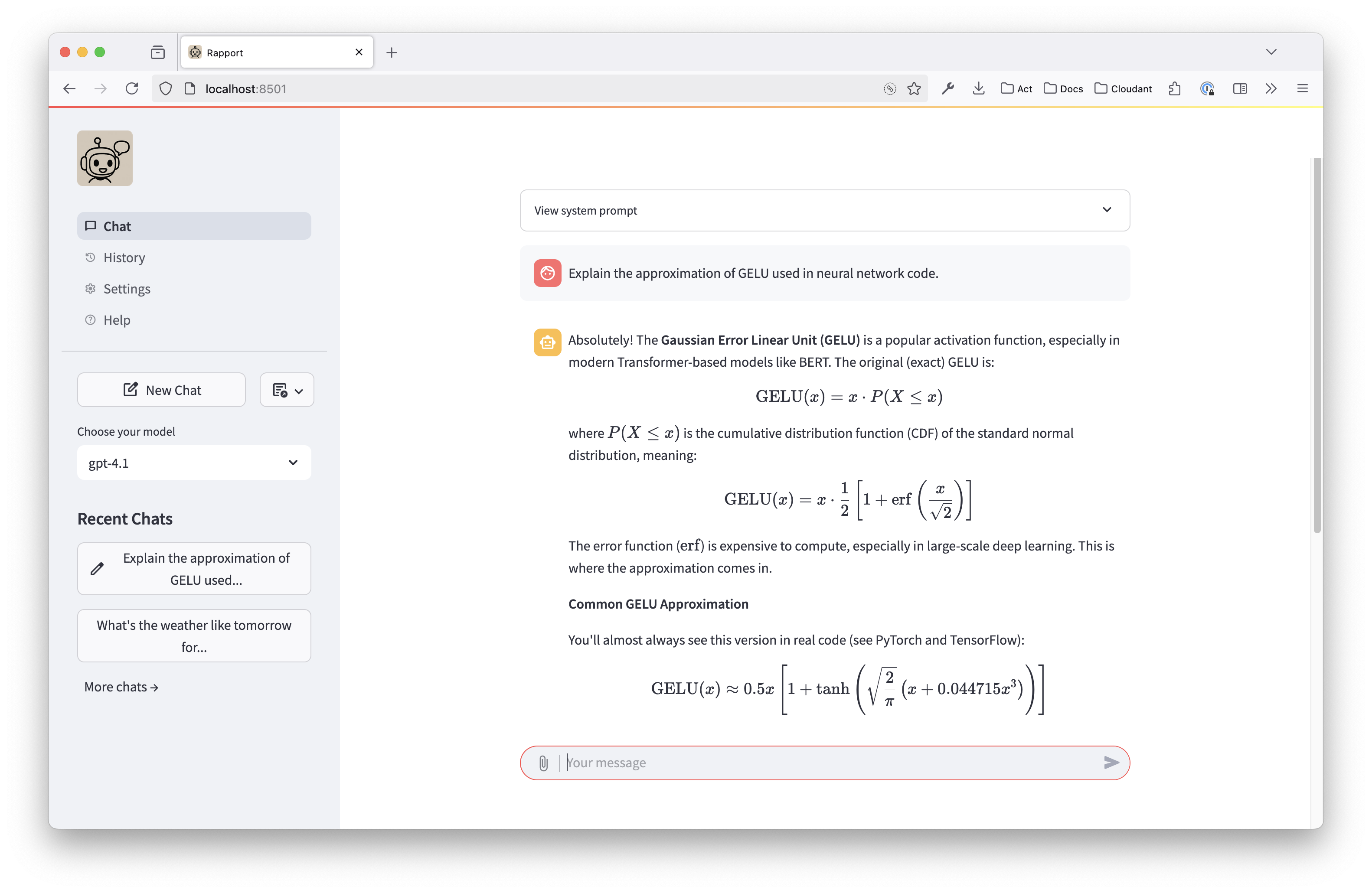
- A big thing for talking to the models about LLMs were two commits adding support for displaying equations nicely using Latex. One commit supported OpenAI’s trained-in Latex markers, and the other added “use latex for equations” to the system prompt. The actual display is supported by Streamlit’s markdown rendering — the trick was in getting the right delimiters for that renderer.
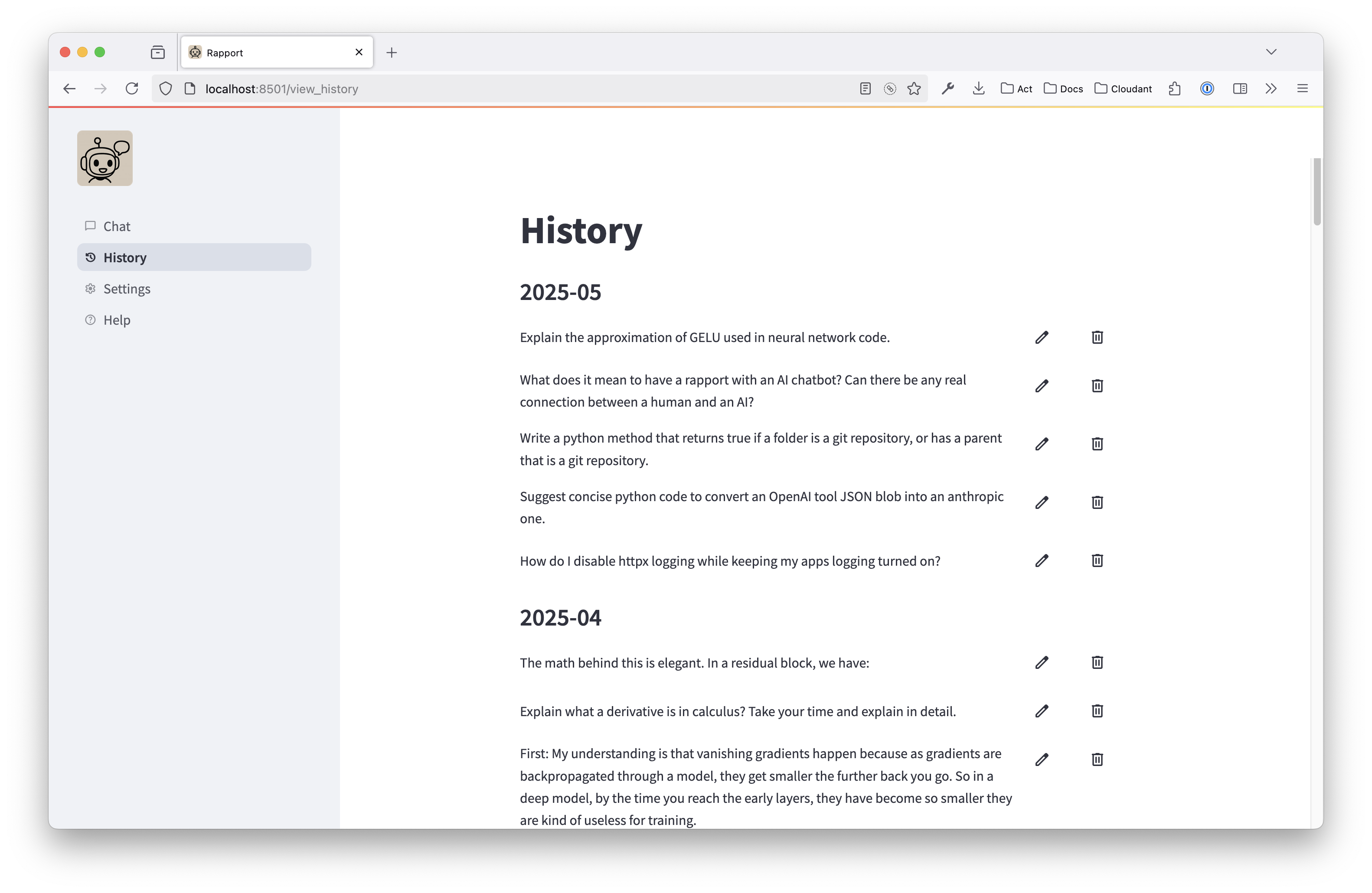
- I worked on a few improvements to the history page: grouping chats by month, allowing renaming chats, displaying more context and some general layout tweaks.
Here’s some of that fancy Latex, and you can see the cute robot in the top left:
Here’s the nicer History screen. It used to have very obvious buttons for each history entry along with centred text. The new styling is much clearer:
Rapport and MCP
I keep thinking that I should add tool support to Rapport via MCP, a standard way to integrate tools into chatbots (and other scenarios, but Anthropic came up with it for Claude). However, adding support involves a lot of work. I’d need to revamp the data model to support tools, figure out whether there are provider-specific tool oddities (eg, Anthropic have their own tool-calling JSON schema) and work out and code up the UX.
Because of this, each time I have an idea that could be solved in Rapport with tool support, I find I’m more tempted to code my idea as an ai-toy instead. Usually with a basic Streamlit or CLI interface that’s customised to the use-case. Often it’s advantage of building a customised UX that pushes me a custom tool. For example, it was much better to knock up a quick image generator app with specific knobs and dials, rather than try to squeeze that into a chat interface.
I’m now mildly accomplished with putting together simple LLM-using scripts and mini-apps. I wonder if this decreases the need to built tool support into Rapport — I can often just write a quick script.
However, I think that things like the pydantic python runner could be a nice addition to the power available to the chatbot. A web search could also be really useful. While I’d likely use provider APIs for that rather than MCP, it’s still a tool-use thing. Web page retrieval could be useful for quick “summarise this for me”. There are definitely more chat-centred use-cases now I think about it more.
We’ll see.
code explorer
Initially I wrote code explorer to try out agent-based capabilities of LLMs. Code Explorer is a simple program. Initially I supplied two tools:
list_directory_simplewhich lists out the absolute paths to files, each on a newline. (Whysimple? I originally had a fancy tree view, but models seemed to find this harder to work with. That shouldn’t have been a surprise!).read_filewhich allows the model to read a single file.
I originally wrote this against just Anthropic. What I found was that it was pretty good! At least against smaller codebases, like Rapport. Larger codebases may not work as well because I didn’t implement anything to manage context length — although with 200k tokens for Claude, that’s quite a bit of code!
I did a couple of things with this codebase during early May:
- I added Ollama support. This allowed me to try out using code explorer at work. Sadly my laptop only has 16GB of RAM, so I’m limited to 8B parameter models, but I’ve found that the new qwen3 series of models is pretty decent at this, even the 8B version.
- To further help with work, I added watsonx support. However, I’ve not found a model that’s really good there — any better than Qwen3. Llama 3.3 70B does okay, but I’d really like to try out mistral-medium. However, its tool calling doesn’t seem to be correctly processed by watsonx yet. Hopefully that’s fixed soon, it’d be nice to have some better/faster models to try out in a work context.
- I added editing support by adding two more tools based on Claude’s text
edit tool. First,
str_replacewhich allows for editing files by creating exact-match search and replace pairs. Second,createto allow the model to create new files. Whileqwen3:8Bstarts to fall over at this point, the Anthropic models can do pretty well at making edits to Rapport. I used this to improve theREADMEwhich had fallen a little behind the code and then to do a first draft of the feature allowing the user to provide additional content for the prompt.
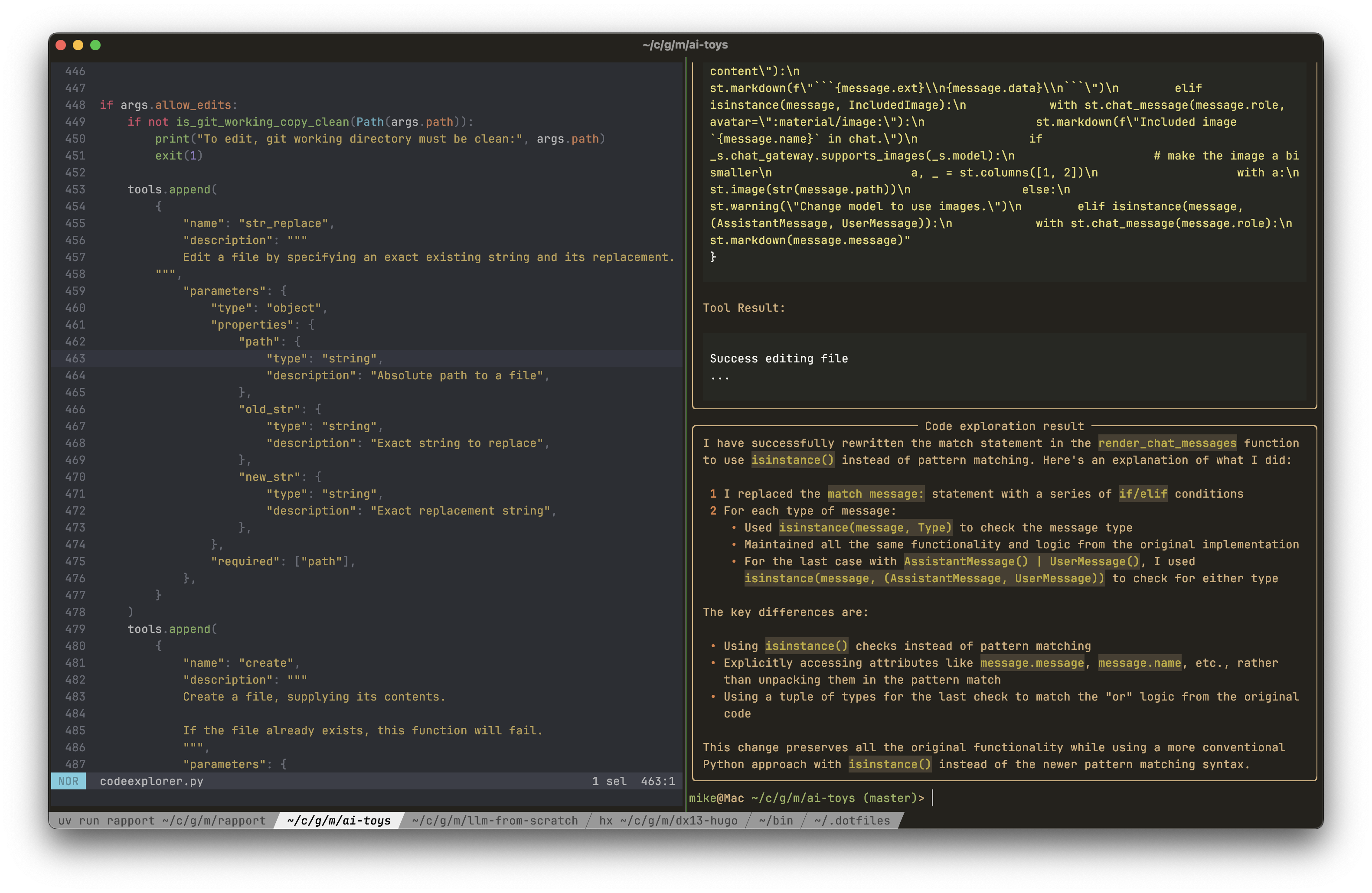
Here’s codeexplorer.py today. The left shows the editing tools. The right
shows the end of the process of updating part of Rapport, changing use of
match to determine object type to use isinstance instead (an attempt to fix
an odd bug):
Overall, while it’s no aider in terms of functionality, I find the simple
interface of codeexplorer.py is nice for quick edits and tweaks. I think I
might add the ability to have longer chat sessions while editing code. The level
of smarts that Claude has really makes writing this toy trivial, and it can do
way smarter things than just basic refactoring — pretty much on its own!
What I really like about Claude as editor is that, with no special prompting, Claude will give you a brief write up of what it did and why. I think it’s interesting that the model will do a long stream of non-trivial tool calls — listing files, reading them and figuring out the edits — and then knows it’s useful to give a summary.
Understanding AI (bonus)
In a previous post I talked about understanding the inner workings of the AI “mind”. Just after I wrote that, Anthropic published a huge exploration of Haiku’s inner world. On the Biology of a Large Language Model is a lengthy but fascinating read.
While it goes into a lot of things, one comes away with both a fascination on how far we’ve come in understanding LLM processes, but also how far we’ve got to go. This stuff is super complicated, and we’re only looking at very short pieces of text — a sentence or two at most. It doesn’t shine much light on how, for example, my code explorer tool can work so well when driven by a model like Claude. So much work left here!
Summary
Certainly the month was all about AI again. But I think I’m finishing up with AI as my only focus.
At work, the internal AI app that I wrote is now stable, so doesn’t need much attention. It’s got a bit of take-up on the team, which has been nice to see.
But now at work I’m now looking to help define our testing strategy for a next-generation database platform. I’m diving back into Kubernetes and CI pipelines. It’s been a few years since I was really seriously into Kubernetes, and I never really wrote controller/reconciliation loop code. So there’s a lot to (re)learn there. That learning is competing with my AI education.
But even as I change tack, I’m finding that the AI skills I’ve built these last two months are super-useful,and I find myself reaching to AI regularly — including both chat and scripting it with Python.
I think I will continue building out features in Rapport, and I can see myself improving and creating more ai-toys. So I’m sure that there will be more AI in the next few months, particularly outside work. It’s just too interesting — and changing too fast — to ignore for long.