At the end of Late May Journal: building things I said I didn’t need, I said:
I’m not quite sure what I’ll do next. I am starting to hanker a little after doing some more work on toykv, finishing up the range-scan functionality I never got working well. Somehow, the browser tab holding “Programming Rust” is still open after not having written any Rust for over a year now. Perhaps it’s time to blow the dust off and get back to it.
Like talking about tools and MCP servers inspired me to write Rapport’s MCP support, just thinking about toykv again stirred up enthusiasm for it.
And so, during June, most of my home coding project hours were spent rewriting much of toykv:
- I updated the on-disk format to use a block-based storage layer.
- I finished up the scan function that allows reading a range of keys. Previously you could only read a single key. The new block-based format involved writing a bunch of iterators that simplified completing this work.
Overall, this made toykv more … real. More like a real database would be structured on disk (though still far from being production quality).
I also found myself having another try at using Zed, as there are now efforts to use the increased focus on Vim functionality to support Helix style interaction.
ToyKV
Going a bit easier on myself
I did two things to make improving toykv easier:
I used the structure, but not the code, of Mini-LSM to help me. The new sstable format is essentially the one suggested by Mini-LSM, but the code that implements it is all my own.
Frankly, when I looked briefly at the Mini-LSM code, it’s clear the author knows both Rust and low-level databases better than me. But that’s the point of this exercise, to help me get better there. So I kept my existing codebase, but made use of the thought that’s gone into Mini-LSM.
One really useful aspect of Mini-LSM has been allowing me to make toykv more sophisticated without implementing all the bells and whistles. For example, I’d shied away from a block solution because I thought I’d need to implement fixed sized blocks — with overflow for large key-values. But Mini-LSM just has variable sized blocks, so large KVs can just take up a single large block. License to do something slightly easier was super-helpful in getting me started once again.
I used Claude to write a lot of tests. I think the codebase is a much stronger for that, and it uncovered a few bugs. Having Claude write most of the tests (albeit with quite a lot of corrections by me) allowed me to write more robust code while keeping the project “fun” given its home-project status. Claude was definitely happier writing a large set of edge-case tests than I would’ve been.
(Claude’s testing did not find the long-standing bug I found with WAL reading. To be fair, I wasn’t asking Claude to test the WAL paths. But Claude definitely tends to test the code as written rather than the code as intended. This probably offers support for the thesis in The Sacred Rule: Humans Write Tests, at least for production code.)
By using both of these resources, I was able to keep moving forward a bit more quickly, while still doing the learning that I wanted to do.
Using a block format for sstables
Previously toykv used a super-simple on-disk format. It wrote key/value pairs to disk in a simple stream format. To search an on-disk table, the code read from the start of the file to find the required key.
The new format differs in two ways:
- Key/values are written to 4KiB blocks. With the caveat that large key/value pairs (larger than 4KiB) create large blocks rather than spreading across several blocks.
- The sstable is written with a block index. At the end of the file is a list of each blocks start offset and the key range in each block.
The block index is the key change: for retrieving an individual key, we can use a binary search on the block metadata to go direct to the right block. This produces a nice speed up.
I have a simple benchmark that writes out 25,000 k/v pairs with a (low) 1,000 k/v pair threshold for writing new sstables. This means that there are 25 tables on disk to search.
I also altered this benchmark to try a 10,000 k/v pair sstable, because this should show a big improvement when able to use a binary search within the sstable rather than linear scanning of the file. And it did show a big speed up!
| Implementation | k/v pairs in sstable | Single doc lookup |
|---|---|---|
| Old | 1,000 | 0.300ms/read |
| New | 1,000 | 0.195ms/read |
| New | 10,000 | 0.065ms/read |
The new format speeds up reads significantly. Increasing the size of the sstables increases it still further. I did try 100,000 items, but the read latency stays similar. Clearly there is another bottleneck somewhere. Still, a ~5x speed up is nice!
Fixing a gnarly bug in WAL reading
The WAL file format has been around since I started working on toykv; it’s not taken from Mini-LSM. I found a bug that’s been there since the beginning.
While doing the benchmarking above, I found that if I had more than 11,397 entries in my WAL, then my WAL reading code would fail to read beyond entry 11,397. Whether the WAL had 11,398 entries or 300,000 entries. I found this super-weird to start with. After all, 11,397 isn’t a magic number that I’ve ever heard of — not a power of two or what have you.
And this would be a serious bug! Because the WAL was effectively being truncated when opening a database with a WAL containing more than 11,397 entries, you would experience data loss. Even though the data was on disk, the database could no longer read it. Even worse, if you continued writing data, the memtable associated with the WAL file would eventually be written to an sstable on disk, and the WAL file would be deleted. Real data loss (without disk forensics, anyway).
Ouch!
It took me a while to fix it. Finding the problem required tracing through almost all the WAL reading code.
The WAL is structured on disk as a series of WAL records, each of which contains a single write to the database. The bug turned out to be in the code that read bytes from disk into a WAL record. This is the deepest method in the WAL read path. It took a decent amount of printf-debugging to get me there 😂
My code can be found here, and looked like this:
let mut header = [0u8; 9];
let n = r.read(&mut header)?;
if n < 9 {
return Ok(None);
}
This reads the header for the WAL record from the file. The header contains a few things that enable the record to be read; the exact content doesn’t matter for this bug.
Here, I assumed (wrongly) that “wasn’t able to read nine bytes” meant “we
reached the end of the file”. Hence the Ok(None). But what I’d missed was that
read doesn’t have to fill the entire buffer. This was my oversight, partly not
being familiar with Rust or low-level byte-reading code, and partly just because
I hacked this out quickly.
What was happening was that at record 11,398 (ie, the failing call) the read
call returned only seven bytes. Because read doesn’t have to fill its buffer,
I should have been issuing another read call to read those other two bytes
rather than immediately bailing.
Obvious to anyone who spends their time doing this level of I/O, perhaps, but not for me this time around.
In my test cases this worked fine: I’d only been working with WALs 1,000 records
long, so this “not filling the buffer” condition really was only hit when we
finished reading the file. So my bug was masked! As soon as my WAL files crossed
some size threshold, read would return after reading fewer bytes, even if
there were more bytes in the file. My guess is the OS hit a page fault (or
something like that) and interrupted the read call.
Now, as noted, what I should have been doing all along trying to read the
remaining bytes from the header. After realising what I’d done wrong I was going
to write that loop, but it turns out that Rust already has a method that does
just this: read_exact. In addition, read_exact only fails when something
weird goes wrong, so my code becomes both correct and simpler:
let mut header = [0u8; 9];
r.read_exact(&mut header)?;
Nice! It took a while to track this down — and to fix the other places where I
read a fixed size header using read rather than read_exact.
Where I’d like to get to with toykv
There are several things I want to get done before I feel I’ll have completed the learning experience with toykv:
I’d like to add Bloom filters to sstables (eg, with ozgrakkurt/sbbf-rs-safe).- Got to this before I published! PR#10 · mikerhodes/toykv. This also offered a decent speed up, particular with large (>100) numbers of sstable files.
- I’d like to get at least a simple compaction scheme working. The simplest being compaction of all the sstables I’m currently writing out to “L0” into a single sorted run at “L1”. A “sorted run” is a set of files covering the whole key space, where each file contains its own portion of the key space. Mini-LSM has some really good guidance on this, so I’m looking forward to getting my teeth into it.
- It would be great to handle multi-threaded access. Again Mini-LSM has some details on this. As I didn’t build in support for threads from the start, this could turn out to be quite involved.
We’ll see how it goes. I’ve spent 6 months now coding (or writing blogs) for an hour each evening. It might be nice to read some fiction again for that hour instead. Compaction also looks quite involved, so I might need a break before getting to it.
Zed (again, and again, and again)
I have an ongoing fascination with editors. Zed has attracted me ever since it first appeared. It prioritises things I want: performance, a strong keyboard focus and batteries included. The very same things that have kept me working in Helix for a couple of years now.
So I keep coming back to Zed, again and again. I try it every couple of months. It’s consistently good, and I do come back to it regularly for a few use-cases, particularly when I want to view files side-by-side to compare them. I just find that easier with a mouse-driven UX.
But Zed’s Vim support was lackluster, and that was a deal breaker. This year, however, that has changed. The post Vim Roadmap 2025 on Zed’s Blog shows how Vim support has improved over the last year, and makes it clear that Vim is a focus for the Zed team now.
Even better, the Zed community has started to use some of the primitives created for Vim support to build out the beginnings of a Helix mode for Zed. I have a strong preference for Helix’s editing model over Vim’s, and Helix’s multi-cursor support matches well with Zed.
So far, the Helix support is … so-so. It’s really promising, but there’s
enough missing for it to be jarring. Some things are missing, like m s ( and
friends to surround a selection with a character. And some things are buggy; at
the moment, for example, going in and out of insert mode moves the cursor when
it shouldn’t.
However, the renewed interest in creating a first-class modal editing experience in Zed fills me with excitement. I love Helix, but Zed is moving faster. While I’m not going to move yet — or perhaps ever — for the first time I’ve bothered to spend some time really poking through Zed’s settings and making it more comfortable to work in. Comfortable enough that I could imagine using it as my daily driver.
That’s a big change in my feelings towards Zed from six months ago, where I didn’t see it ever playing more than a bit part in my life.
Regardless of the fact that I’m a bit changeable when it comes to exactly what editor I use, it’s pretty clear how I want my editors to look — just compare these two screenshots, first Zed then Helix 🤣:
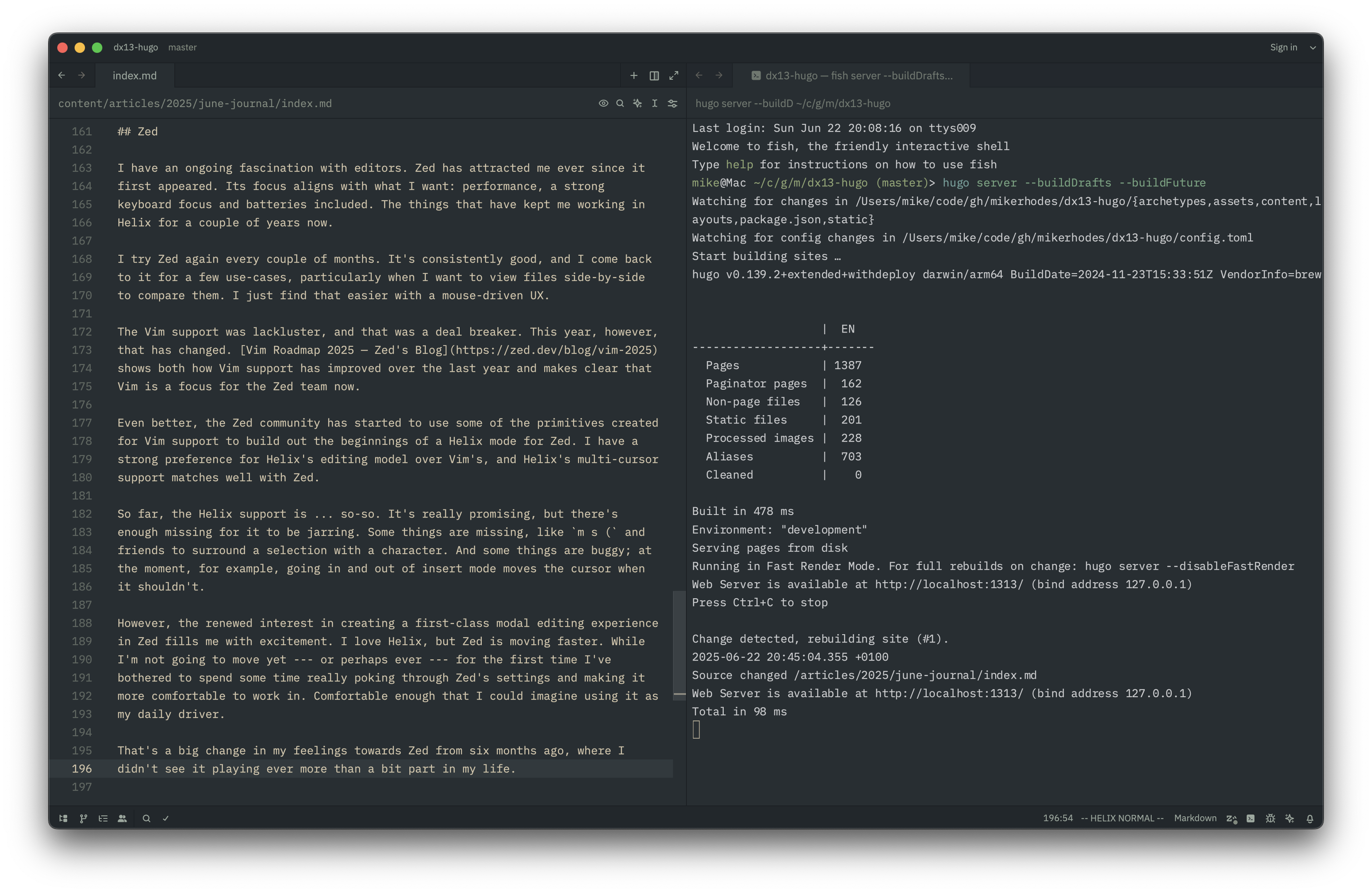
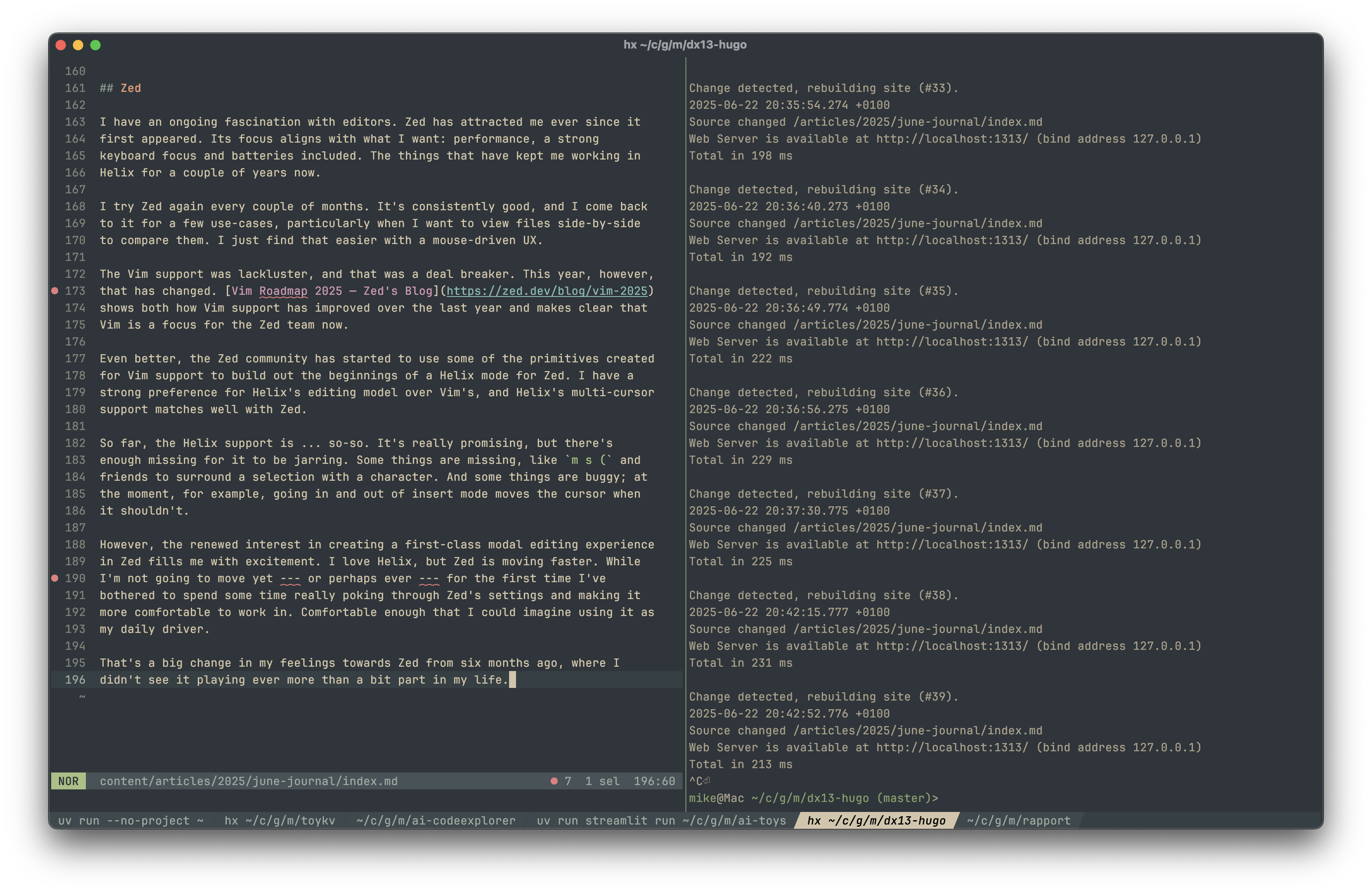
From this, it seems to me that I want Zed to look like a terminal editor. Which is, perhaps, why Helix may still win out.