I finally got to reading Paul Ford’s opinion piece in the New York Times, The A.I. Disruption Has Arrived, and It Sure Is Fun. I’ve long nodded my head to Paul’s essays, and this wasn’t an exception.
Especially this part near the end, which gels with my (naive?) hopes about AI reducing the amount of software suckiness in people’s lives:
I collect stories of software woe. I think of the friend at an immigration nonprofit who needs to click countless times, in mounting frustration, to generate critical reports. Or the small-business owners trying to operate everything with email and losing orders as a result. Or my doctor, whose time with patients is eaten up by having to tap furiously into the hospital’s electronic health record system.
After decades of stories like those, I believe there are millions, maybe billions, of software products that don’t exist but should: dashboards, reports, apps, project trackers and countless others. People want these things to do their jobs, or to help others, but they can’t find the budget. They make do with spreadsheets and to-do lists.
My industry is famous for saying no, or selling you something you don’t need. We have an earned reputation as a lot of really tiresome dudes. But I think if vibe coding gets a little bit better, a little more accessible and a little more reliable, people won’t have to wait on us. They can just watch some how-to videos and learn, and then they can have the power of these tools for themselves.
I hope we can, though what that means for the professional programmer, I don’t know. Clearly there’s a lot of software where “probably right” isn’t good enough, perhaps that is where we will re-find our niche.
I’m interested in how we can create software that’s malleable for people’s needs. I think AI can be a tool to achieve this.
Let’s talk about one aspect of that malleability: how things look. How can AI help with this?
Sadly, by default, AI output is a consistent “non-style”. Even Anthropic call it “AI slop”, suggesting breaking this mold by telling the model:
You tend to converge toward generic, “on distribution” outputs. In frontend design, this creates what users call the “AI slop” aesthetic. Avoid this: make creative, distinctive frontends that surprise and delight.
Later, Anthropic note that some hallmarks of this style are large border radius, system fonts, and (oddly specific!) purple gradients. I tested this out with a few prompts.
I quickly knocked up a demo app to show this. Its purpose is telling you how long a given size of integer will take to rollover, which can cause problems. But what we’re interested in is how it looks, which… isn’t great:
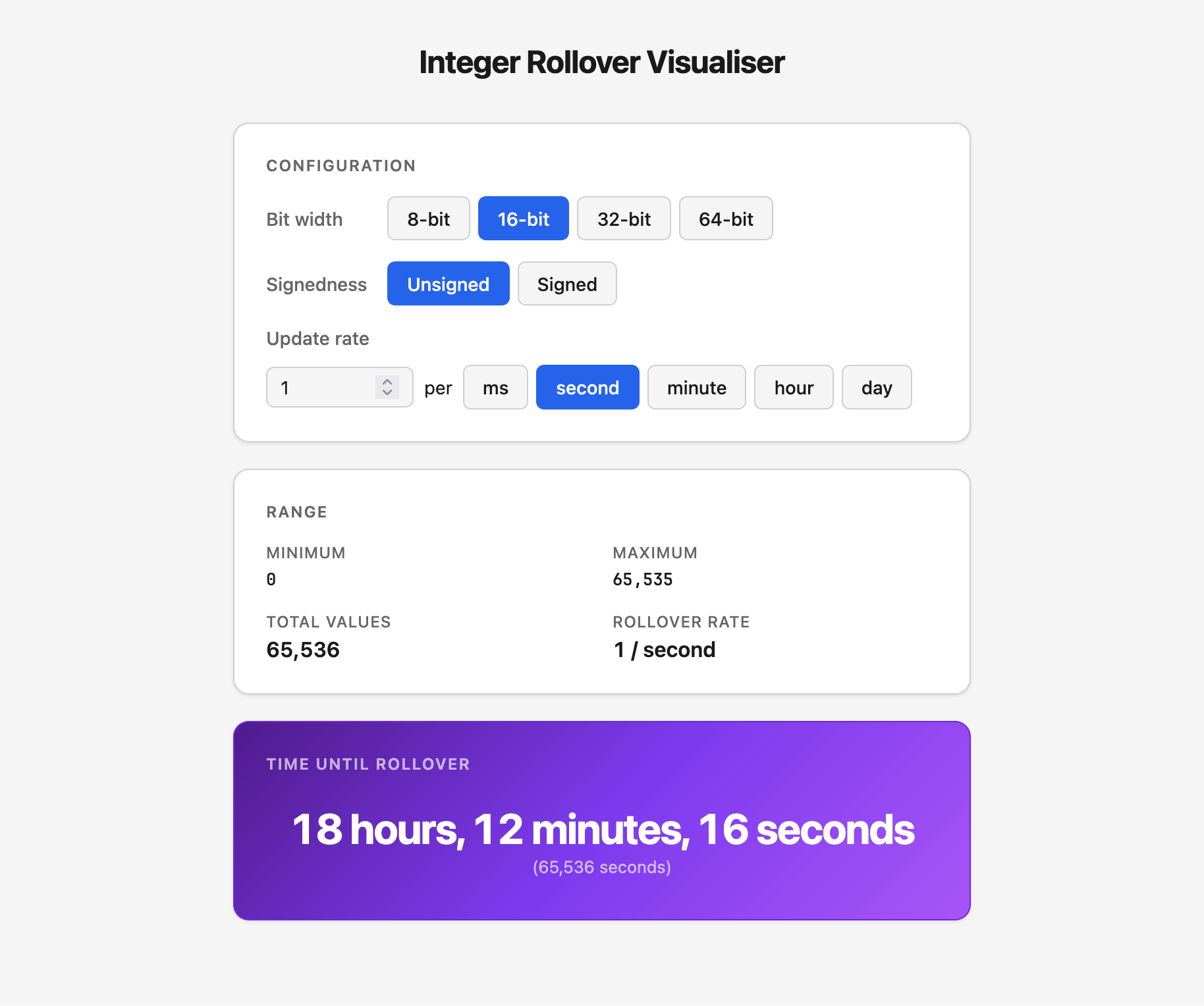
- Large border radius — check!
- System fonts — check!
- Purple gradient (🤷) — double-check!
But thankfully this is only what comes out of the model by default. With a little work, we can steer the model towards much improved designs.
So how can we bend the styling to our will? One way I’ve come up with is: write a Claude Skill that contains a design system using a style I like. Here’s the result:
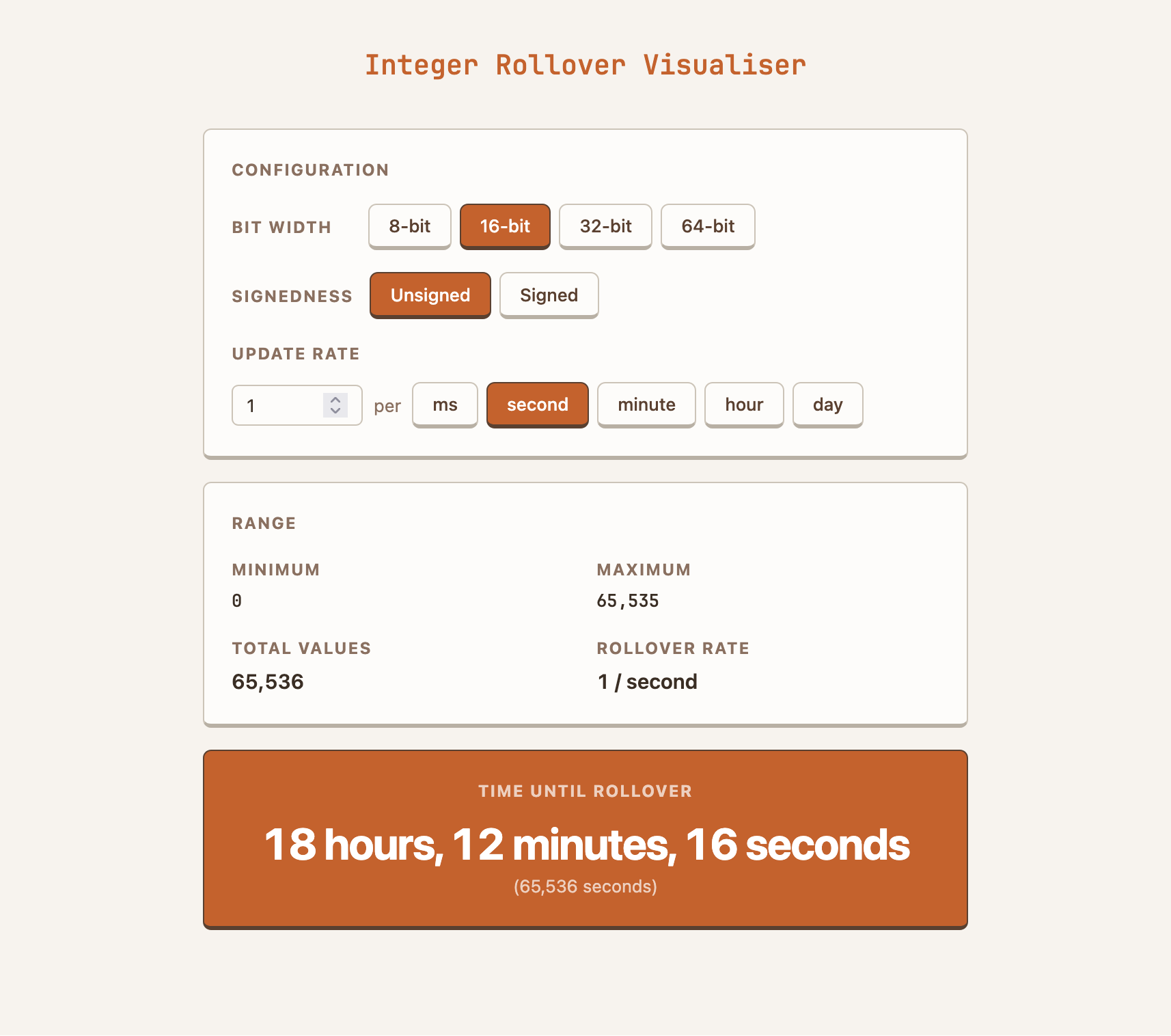
Same layout, nicer design. At least for my tastes. But this approach is easily adapted to whatever your taste is!
Otherwise, read on for how I got the idea, and built it. It’s a bit of narrative rather than a guide, but it’s got lots of screenshots and prompts to inspire along the way.
My thoughts turn to the analogy of a car.
A car can travel at 140mph. But if I went that fast I’d drive into a wall. Driving at the maximum speed of the car is counter-productive. Instead, I have to remain at human-compatible speed.
AI codes at 140mph. I believe that’s not human-compatible. Perhaps we will find a way to harness that speed; to make it human-compatible. More likely we will find that certain tasks can go that fast, and others can’t. 140mph is okay on a race track but not on a back street.
We do not have to force ourselves to adapt to the speed AI can generate code at. We do not have to travel at theoretical maximums. Driving at normal speeds is still much faster than walking. In the same way, we can write code faster with AI help, even if that help is not at top speed.
If we don’t insist on top speed, AI code might even be better than we’d write alone.
Wouldn’t that be nice?
I’ve make this point in work Slack a few times. Carson Gross says it better though:
Some people say that the move from high level languages to AI-generated code is like the move from assembly to high level programming languages.
I do not agree with this simile.
Compilers are, for the most part, deterministic in a way that current AI tools are not. Given a high-level programming language construct such as a for loop or if statement, you can, with reasonable certainty, say what the generated assembly will look like for a given computer architecture (at least pre-optimization).
The same cannot be said for an LLM-based solution to a particular prompt.
I think it goes a bit deeper than determinism, however. In some way, high-level , assembly and machine code are merely alternate representations of the same thing. They encode the same information. If the CPU could directly run Rust code, the same thing should happen as when it runs the compiled machine code.
Compilation is translation that, at best, preserves existing information; it may even discard some. In contrast, LLM’s create new information from their inputs. Lots of it. This is what makes probabilistic generation a very different beast to deterministic compilation of a high-level language.
I can see where the simile comes from — “human language is a higher level of abstraction” — but it’s not simply a higher level of abstraction. It is a completely new mechanism to create programs. Instead of translation, it’s generation.
Code produced today will differ from code produced yesterday for the exact same prompt and model. And that non-determinism is the essential aspect of the LLM paradigm; it gives the approach its excitement, its power and its weakness.
This is why we don’t know what to do with it. If it was merely a higher level abstraction, well, we’ve done that a hundred times before.
My last post captured my feelings and thoughts on AI. It’s also worth capturing how I use AI, specifically GenAI (as if that needs saying at this moment).
If I were to place myself on the Steve Yegge Gas Town 8 Point Scale of AI programming, I’d place myself between 5 and 6. I run Claude Code in the background and regularly give Claude deep research assignments.
At work, IBM has only just granted me access to its coding agent, IBM Bob. But I’ve been able to start quickly by using my experience using Claude Code at home.