They call them “god rays” when the sun pokes shards through cloud. I find they are often too subtle to catch on camera, but the black and white of this shot captures them perfectly.

Clifton suspension bridge, Bristol.
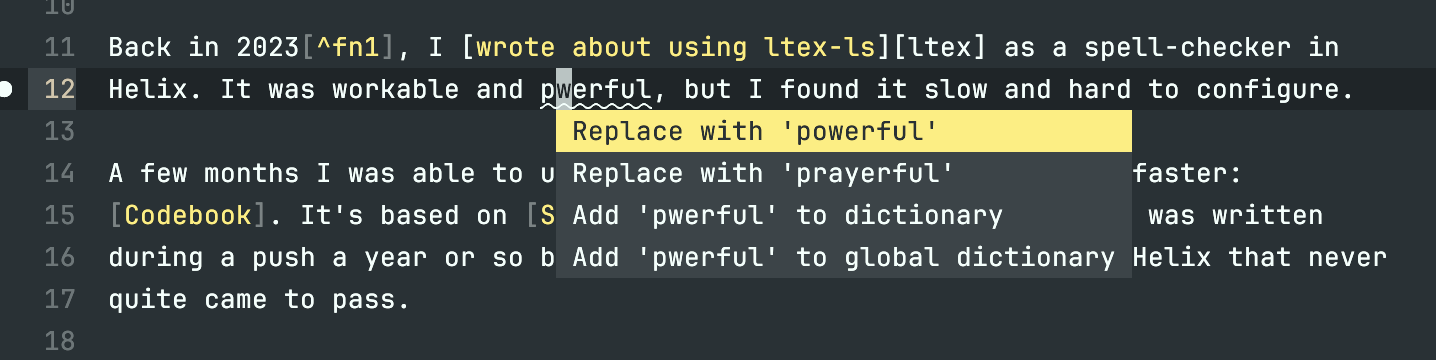
Back in 20231, I wrote about using ltex-ls as a spell-checker in Helix. It was workable and powerful, but I found it slow and hard to configure.
A few months I was able to upgrade this to something leaner and faster: Codebook. It’s based on Spellbook, which (mildly ironically) was written during a push a year or so back for inbuilt spelling support in Helix that never quite came to pass.
I highly recommend it. Codebook is a code spell-checker, so it recognises coding
idioms like snake_case_names and camelCaseNames, and uses tree-sitter so
it’s sensitive to what the purpose of each token is — so it doesn’t flag
keywords as bad spellings, for example. Codebook works great for markdown, too.
Once this is all set up, you’ll be able to hit space + a for completions:
After the fold is my configuration for a few (programming) languages in British English.
After writing about cgroups, it’s hard not to get sucked into the rest of the low-level Linux technologies that make up containers. In addition to cgroups, the main other technology is namespaces, which give processes different views of critical system resources.
For example, the mnt namespace allows us to isolate what mount points a
process sees (eg, give the process a new root file system — including special
mounts like proc), while the cgroups namespace allows us to isolate a
process completely to a new cgroup hierarchy. Other namespaces form further
pieces of isolating containers from each other and the host system. I hope to
write more about namespaces, and build a bare-bones container runtime.
(When writing the cgroups article I wondered how to prevent a process “escaping” its cgroup. I think this is our answer: give it its own cgroup namespace, and it cannot move itself outside its original cgroup).
For this post, we’ll look at the net namespace. There’s quite a lot to talk
about here, because in addition to the isolation provided by the namespace,
there are a number of low-level networking constructs we have to scaffold up to
allow a process in a namespace to talk to other network namespaces, the host
machine and, finally, the public internet.
What do I hope to gain? By piecing this together, admittedly by mostly adapting others’ work to my specific goals, I hope to get a more solid understanding of how container networking works, to help ground my mostly theoretical knowledge of Kubernetes overlay networks.
Let’s go.
In my idle moments, as I sit quietly and watch clouds scud across the sky, I sometimes wonder things like:
“Inside Kubernetes or whatever, underneath containers and all that fancy stuff, it’s just the kernel’s cgroups v2 holding things apart from each other — if I was writing some Go code, what’s the best way to put a process into a cgroup to limit its resources?”
Now, I know a lot of the theory here. I’ve read the cgroups v2 documentation and know how it fits together, that it’s filesystem-based and what the various controllers can do for you. And I know the broad strokes story of what and how you manage resources. While I could definitely know more about namespaces, I do know enough to know that namespaces are what I need to reach for if I want to put some decently hard isolation boundaries between processes, albeit not ones you’d probably want to use for untrusted process execution. I can use this knowledge effectively when building stuff in Kubernetes.
But I want to start grounding this theory in practice. Write some code that does the stuff rather than just knowing about the stuff. Because that’s when you really get to know the details of the thing, and can exercise and test your reasoning about the world.
So let’s start by taking a look at this little specific corner of Linux, how do we put something into a cgroup? I took a slightly circuitous path when figuring this out, and, as I like reading similar detective stories, I’ll write out what I did. Finally, let’s get specific about what we want to do:
- Rather than figuring this in the abstract, let’s write some Go.
- We’ll deal exclusively with cgroups v2 as most distros enable it.
- And we will deal with this single question, rather than covering all the functionality cgroups has — because you have to be able to put a process into a cgroup before you can do anything else.
First we’ll see the naive way to do it, following the process in the cgroups v2 documentation. This way works, but has an annoying imperfection about it. Next we’ll look at a way that doesn’t have the problem, but which turns out not to work in Go. And finally, we’ll use some relatively recent additions to Go to make it work neatly.

Last night I went to see the Nova Twins in Bristol. We were super-excited; Nova Twins were on our “love to see” list. And we were not disappointed: it was excellent, intense and exhilarating, just as rock-metal should be.
🤘
Take the chance to see them if they play near you.